
在系统中应用机器学习模型时,一般将每条下发的物料作为样本,其中获得用户正反馈(点击)的作为正样本,没有获得用户反馈(无点击)或者负反馈(skip)的作为负样本。
这种处理存在以下几个问题:
- 由于网络丢包等原因,下发的物料,不一定真实出现在APP/网页上。
- 用户的反馈可能受到position-bias的影响,排在前面的物料往往容易获得更多的点击(伪点击),而排在后面的物料可能用户根本就没注意到它(伪曝光)。
第一个问题,可以通过加载上报将丢包数据清洗掉(需处理重复上报和上报丢失的问题)。
第二个问题,可以引入click model,假设用户浏览行为,对物料的真实曝光/点击建模。
Basic Click Models
baseline
- Random click model:假设点击是一个纯随机事件,点击的概率为固定值。
- Rank-Based CTR model:假设点击只跟位置有关,每个位置有自己的点击率。
- Document-Based CTR model:假设点击只跟QU(query-url)对的绝对相关性有关,每个QU对有自己的点击率。

Position-Based model
- Mixture Hypothesis:假设一部分点击来源于位置,一部分点击来源于绝对相关性。点击率等于两者加和。
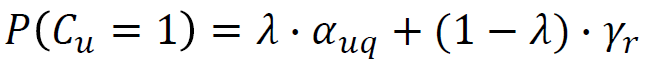
- Examination Hypothesis:假设物料的真实曝光和曝光后是否被点击为独立事件。物料的真实曝光概率由位置决定,曝光后是否被点击由绝对相关性决定。
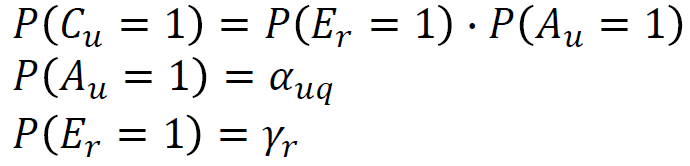
Cascade Family
Cascade Family都假设用户从上往下依次浏览,不同变种的diff在于(点击/未点击)继续往下浏览的概率不同。资讯被浏览后,是否被点击由绝对相关性决定。
- Cascade Model:假设用户首次点击后,不继续往下浏览。
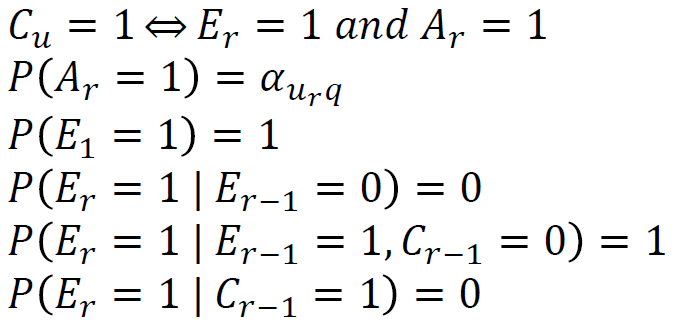
- Dependent Click Model:假设用户点击后,根据点击位置,有一定的概率继续往下浏览。(处理多次点击的情况)
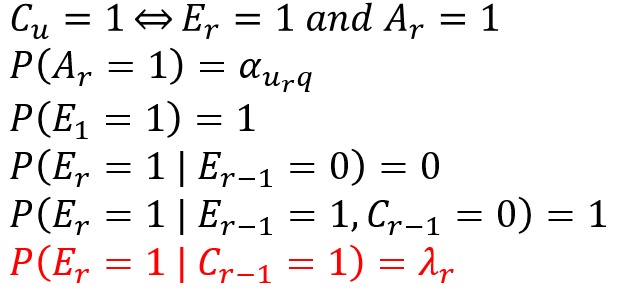
- Click Chain Model:假设用户点击后,有一定的概率继续往下浏览;用户没点击,也有一定的概率继续往下浏览。(处理整个session没有点击的情况)
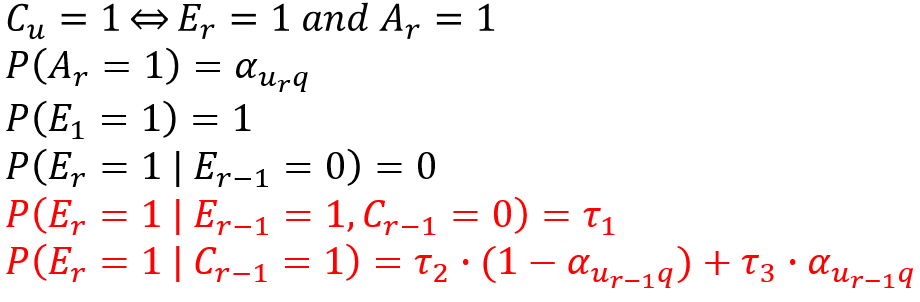
- Dynamic Bayesian Network Model:引入用户满意度,用户点击后根据QU对,有一定的概率被满足。用户被满足,不再继续往下浏览;用户未被满足,有固定的概率继续往下浏览。
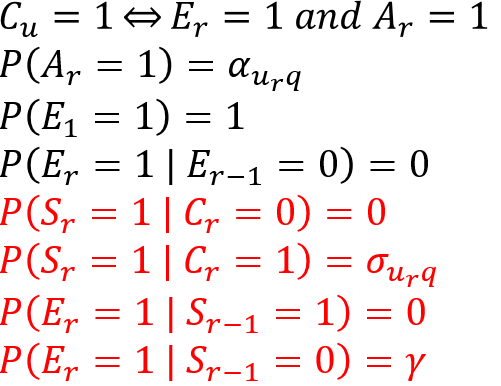
Application
Implicit application
- 使用后验词典做CTR预估:Document-Based CTR Model
- LR中使用位置特征:Position-Based Mixture Hypothesis
- 根据click/skip做数据清洗:Cascade family
Explicit application
Click Model with E&E
Cascading Bandits: Learning to Rank in the Cascade Model, 2015, Adobe.
DCM Bandits: Learning to Rank with Multiple Clicks, 2016, Adobe.