最近几个月在项目中引入了基于 TensorFlow 的 Online Learning,本文介绍下基本原理和实战中踩过的坑。
1. TensorFlow
主要看官方文档和API就行,这里只简单记录下有意思的特性。
Gradients computation
和大部分的 DL 库一样,采用链式求导,自带的 OP 中都已经包含了 gradient 的求解,我们在使用时,只需要搭建 forward 的求 loss 的图就行,然后选择优化器去训练就行。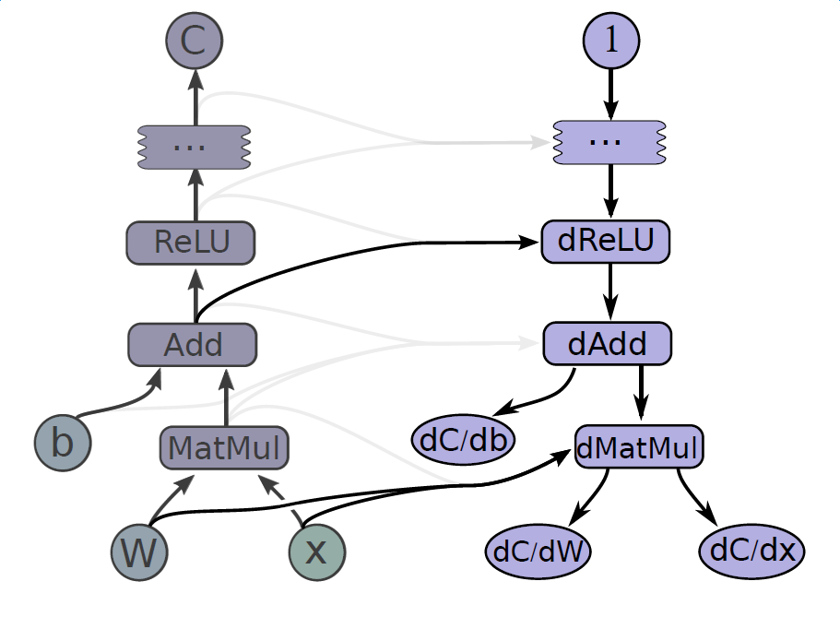
Partial Execution
根据 client 指定的 fetch,自动查找依赖,进行部分计算。一方面避免了无效的计算,另一方面实现了图的”多态”(例如,图中e和f可以分别是模型的训练和评估。)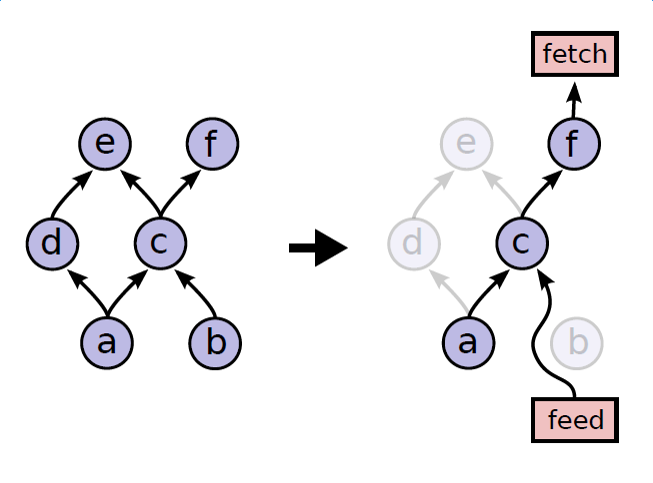
Parallel training
和其它的分布式计算一样,参数同步有异步和同步的两种形式。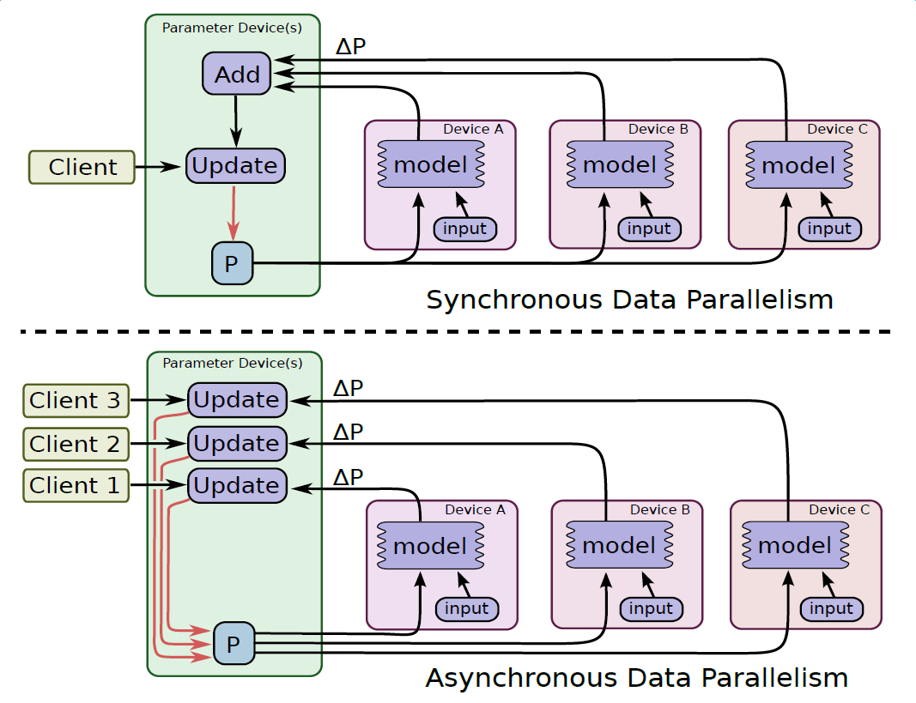
Queue
Queue可以作为一个缓冲区,实现数据预处理和模型训练的并行。
2. Online learning
overall structure
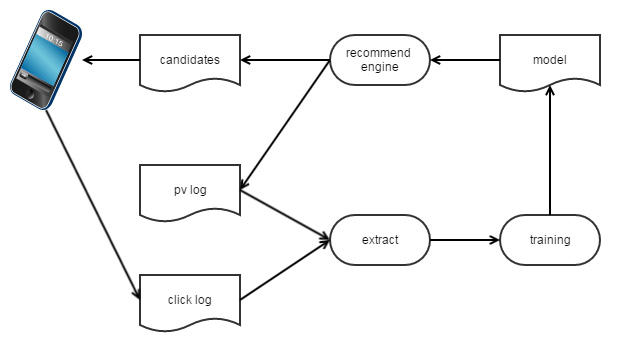
online learning是一个相对于offline learning的概念。
- 在 offline learning 中,图中的 extract 为 ETL 定期收集日志并提取样本;training 为模型的定期训练 batch training 或者 increment training。
- 在 online learning 中,图中的 extract 为实时样本流;training 为模型的 online training。据说凤巢已经做到了流式的训练样本,直接更新线上的 model;我们的实现为流式的训练样本,定期export模型然后推到线上 reload。
实时样本流
- 使用 kafka 实时收集服务器生成的 pv log 和客户端实时上报的 click log.
- 使用 storm 流式的提取特征.
- label 确认:用户的反馈行为上报是有延时的。我们的实现中采用延时确认方式,收集到 pv log 后先提取特征,然后等待 15 分钟(具体时长是 label 正确性和样本流时效性的 tradeoff),如果收集到对应的 click log 则生成正样本,否则生成负样本。在 twitter 的一篇文章中,收集到 pv log 中马上产出一个负样本,收集到 click log 后拼接上 pv log 产出一个正样本,这样做引入了一些”错误的负样本”但提高了样本流的时效性。
online training (based on TF)
- TF支持长期学习,定期产出 checkpoint,而且支持 checkpoint 热启动。要实现 online training,只需要将数据流式的灌进去就行。
- Queue:用一个 FIFOQueue 作为缓冲区,训练流程的触发的第一个 OP 为 dequeue 操作,如果 queue 为空,则 hang 住等待,如果 queue 有数据,则进行训练。
- kafka reader:另外启一个线程,通过 kafka reader 从 kafka 中读取数据,执行 enqueue 把数据塞进去。
收益分析
- 提高时效性–>降低 variance。
- 适用场景:数据分布变化大(e.g. 资讯推荐)
3. 实战指南
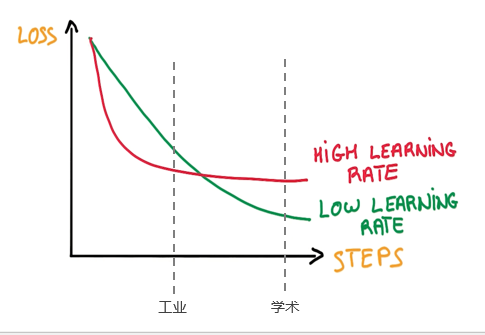
- Online learning 在工业应用时,受限于时间,往往无法充分训练,用一个相对大的学习率,效果可能会更好。
- FTRL 相比于 OGD 有两个特性,a.稀疏解,b.学习率衰减。其中在工程中a是很有用的,但是b在某些场景会造成模型固化,例如:在新闻推荐里,对时效要求很高(今天受欢迎的推荐,明天继续推也许会是badcase),但是学习率衰减后,需要更多的badcase样本才能让模型修正回来。所以可以将lr_power调整为0.0,在保障稀疏解的同时,缓解模型固化现象。