
读了几章 Andrew NG 新书 Machine Learning Yearning,非常适合实战,本系列记录相应的读书笔记。
// NG 终于更新了
Chapter 1~19
Train/Dev/Test sets
工程项目中,Train-set 和 Test-set 的生成需和线上保持一致,单纯的随机抽样并不一定适合。
e.g. 资讯推荐系统中,我们拿历史一个月的日志,随机抽样生成Train-set和Test-set,离线会得到很高的AUC指标,但是线上效果却不行。
分析原因,资讯推荐实际下发的大部分下发的物料都是新资讯,在历史日志里是找不到的。更合理的是拿前29天的数据作为 Train-set,第30天的数据作为 Test-set。
使用 Dev-set 调参/模型选择,使用 Test-set 评估
Dev-set 和 Test-set 是用的同一份,很容易出现overfit Test-set的情况。只在特定的评估集上效果好,换一个评估集就不行了。
调参/模型选择只在 Dev-set 上进行,一定不能用 Test-set,不然 Test-set 又变成 Dev-set 了。
一旦出现 overfit Dev-set 的情况,就换一组 Dev-set 和 Test-set。
Dev/Test sets 大小设置
下限:足够体现 diff。不设上限,但是过大会造成浪费,影响迭代效率。
e.g. 分类精度从 90.0% 提高到 90.1%,则起码需要 1000 个样本才能体现 diff。为了消除波动,可以加大到 1W。但是没必要加大到 1KW,影响迭代效率。
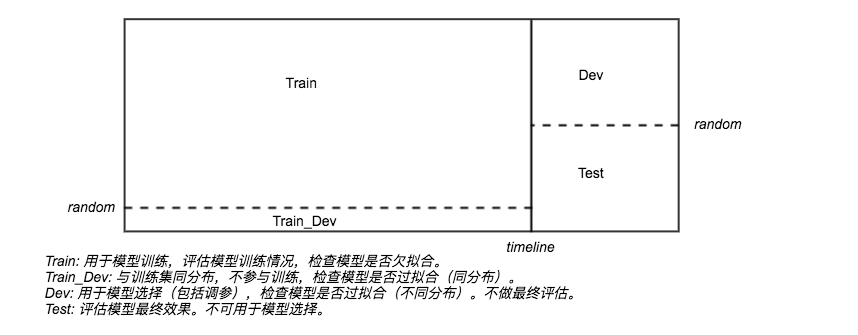
考虑添加 Train_Dev 集,如下图所示。(个人思考,书中没写)
One Single-Number Evaluation Metric
单评估指标!!多评估指标很难判断哪个模型更优。
Precision+Recall –> F1 score
Weigthed average
约束条件 vs 优化目标
有些评估指标可以转化为约束条件:e.g.运行时间,模型大小。
拆解出约束条件后,再将多目标转化为单目标优化。
Basic Error Analysis
- 小步快跑:快速搭建 baseline。
- 循序渐进(in parallel & iterative):看 case 非常重要。找到瓶颈,寻求突破点。
反例:猫分类问题
当前错误率是 10%,其中只有5%的错误分类是“狗”误判。花一个月时间解决狗误判问题,精度只从 90% 提升只 90.5%。
Q&A:排序问题的 case 怎么归纳?// TODO
Cleaning up mislabeled Data
- 看影响面,如果 mislabeled 成为显著问题,则需要及时修正。
- 数据集同步 fix,起码保证 dev 和 test 同步,保证同分布性。
- 同时修复时分类错误和正确的 mislabeled,如果只修复分类错误的 mislabel,评估还是有偏的,容易虚高。
Eyeball / Blackbox dev set
- Eyeball 人工随机挑选出看 case 的 dev set。(推荐大小:100+ 个 badcase)
- Blackbox 是 dev set 过大,无法(或者没必要)人工全部看,剩下的部分。可以避免 overfit eyeball dev set。
Chapter 20~22
bias variance
- 判断瓶颈是在 bias 还是 variance。
- bias 通过 Optimal error rate (通常可以用人的表现为参照)来计算 avoidable bias。// TODO 排序问题怎么寻找 Optimal error rate?