
Automatic Machine Learning(AutoML) 是近几年一个很火的 topic。
最近我也在做 AI 2B 的工作,总结现状就是“做项目不难,赚钱难”。
ML 技术应用到传统行业,提升非常明显,这就是“做项目不难”。ML 的应用成本太高了,上线和建模成本都很高,这就是“赚钱难”。
上线的瓶颈主要在硬件和开发成本,现在有很多人在做平台,来优化资源管理和避免重复开发。
建模主要还是靠人来做,但是相对 2B 市场的旺盛需求,对口的人还是很紧缺,而且比较贵,所以当前只有头部场景能享受到 ML。AutoML 的目的是降低 ML 对人的依赖,也许是解决 AI 2B 困境的一个关键技术。
传统机器学习
常见的 Pipeline
瓶颈: 重复工作 + 高人力成本 (领域知识 + 算法理论 + 实践 trick)
- 数据清洗 & 数据预处理
- 手动构建和选择特征
- 选择模型
- 选择超参
- 模型融合
- 重复上述过程
AutoML
Modern Hyperparameter Optimization
- 把 autoML 当作超参优化问题
- 条件超参(e.g. momentum for optimizer)
- 黑盒优化: Grid Search、Random Search、Bayesian Optimization(核心是解决 Exploit & Explore 问题)
常见 Bayesian Optimization:
GP (使用高斯过程对 p(y|x) 建模,模型自带 uncertainty)
SMAC (使用 random forests 对 p(y|x) 建模,variance 当作 uncertainty)
TPE (使用模型对 p(x|y) 和 p(y) 建模,其中 p(x|y) 使用根据 y 历史值分位数为界限,上下分别用一个高斯分布来拟合。然后通过后验概率计算 p(y|x) = p(x|y) * p(y) / p(x))
- 黑盒优化之外: 在深度学习或大数据下还是太慢了,也有一些其它方式的尝试。
Hyperparameter Gradient Descent: 建立超参在测试集上的loss函数,然后通过 GD 来优化。
Extrapolation of learning curves: 预估评估曲线,提前预判收敛后的评估指标区间。
Multi-fidelity optimization: 数据抽样,减少训练轮数。
Hyperband: Successive Halving 每训练制定轮数,丢弃一半效果差的超参组。
BO-HB: Hyperband 做资源分配 + 贝叶斯优化选择下一组候选超参。
Meta-learning
Neural Architecture Search (NAS)
- Search space design
cell search spaces: 先定义好一些子 cell,然后对子 cell 进行组合,本质是在裁剪搜索空间。
Unrestricted search space: 只对网络大小上限做一些限制,对具体结构不做约束。
- 黑盒优化: 和上一段讲的超参优化类似,主要方法如下:
Reinforcement Learning
Evolution
Bayesian Optimization
- 黑盒优化之外
Weight inheritance & network morphisms
Weight Sharing & One-shot Models
Multi-fidelity optimization
Meta-learning
Meta-learning
Meta-learning 也常被称为 learning to learn。
我通俗的理解是每次学习当做一个样本,结合多个 domain 的样本,来建立(学习)元数据和模型效果的关系。
主要的实现思路可以分为: recurrent models, metric learning, learning optimizers
AutoML 在 AI 2B 实践
AI 2B 大多数应用场景(特别是在 POC 阶段),机器资源是非常紧张的。AutoML “慢”的问题就成为落地瓶颈了,特别是一些“牛逼”的算法想要用起来很难。反而是一些不起眼的 dirty work 能够带来一些实际帮助,主要是特征工程和超参优化相关的。
我自己的理解,现在的机器学习流程可以分为 human、template 和 auto 三种方式。把它们结合起来用,能会发挥最大的价值。
| 特征 | 模型 & 超参 | |
|---|---|---|
| auto(tools) | Featuretools 等 | TPOT、Hyperopt 等 |
| template | domain feature 模版 | 经典网络结构(e.g. 时序问题用RNN)、传统模型选择(e.g. 连续特征使用GBM)等 |
| human | human knowledge | human knowledge |
Auto-Feature-Engineering
我之前做特征工程的方法主要为”经验” + “case”,这里有很多 trick。
经验: 主要依赖于领域知识和业界的特征处理经验(e.g. 各种连续值离散化,离散值encode)
case: 分析模型打分或线上应用的 badcase,再猜想问题,做优化,最后做实验验证。
Auto-Feature-Engineering: 我的理解是特征模版 + 特征衍生 + 特征选择。
特征模版: 根据领域知识建立特征模版。比如说在 fintech 里面清空余额在很多应用(反欺诈、反洗钱、用户流失预警)中都是一个特殊的操作可以将它加入 fintech 应用的特征模版,又比如说在时序场景里,历史周期性的均值是常见的特征,我们就将历史均值作为时许应用的特征。总体来说,就是把领域内的业务知识沉淀成特征模版;主要视角包括 schema 和问题类型。
特征衍生: 特征的加工主要包括连续值离散化、离散值连续化、特征组合。特征衍生部分可以做成自动化,避免每次都重复建设。
连续值离散化: 常见的为等距分桶和等频分桶。等距分桶的缺点是有偏离点时分桶会出现明显倾斜;等频分桶则需要额外计算分桶点。我个人偏向于等距多分桶 + L1正则,通过设置不同的桶树进行多次分桶缓解倾斜问题,然后用正则来避免分桶过细带来的过拟合。
离散特征连续化: 这里操作有很多,我个人常用的包括 one-hot,pv_ctr embedding(统计历史时窗的 pv 和 ctr),pre-trained embedding (NLP 经常用预训练好的 embedding),joint-train embedding(直接离散特征过 embedding table,然后 embedding 是根据 loss 学出来的)
特征组合: 特征组合操作上很简单,就是做一次 combine 操作,难点在于选哪些特征来做组合。
特征选择: 特征衍生时,需要做一些特征选择,如果纯暴力的做,效率很低,而且会带来噪声,影响学习效果。我的做法包括以下4个步骤,根据资源的情况,可以多次重复,终止条件可以为重复次数或全量特征效果没有提升。
- 核心特征筛选: 通过 slot-wise lr 或者 GBM 做特征重要性评估,选出 Top K 的核心特征。
- 核心特征衍生: 将核心特征通过上述方法得到衍生特征。
- 衍生特征验收: 将衍生特征做单特征评估,将重要的特征保留。
- 全量特征评估: 将验收特征加入特征集合,评估新全量特征效果。
以我做过的一个反欺诈项目为例说明,说明下 Auto-Feature-Engineering 的落地流程。没有高深的算法,就是一些自动化流程和工具积累,整个建模成本就可以大幅下降。
- 使用特征模版生成原始特征,从 schema 上可以生成是否大额交易等,从问题类型上可以生成历史同期转账金额等。
- 离散值 pv_ctr embedding。
- 连续值归一化、多分桶。
- 使用 slot-wise lr 做特征组合。
- 使用 GBM 做特征筛选。
- 将 GBM 选出来的 Top 40 离散特征做 joint-train embedding,连续特征接入 Deep,离散特征接入 Wide,构建 Wide & Deep 模型。
超参优化
超参优化我用的比较多的还是 hyperopt,“速度快”(支持 tpe), “成本低”(接口友好),
工具大家应该都比较熟悉,这里就不展开说了,分享一个 trick 和坑吧。
trick: 一切皆可超参化。举个实际的例子,在销量预测的场景里,label 的数值变换,是否要分组训练等都是一些可以尝试的点,同一组模型超参需要跑很多组实验。在当时的项目中,相对数据量来说算力还是很充足的,所以可以比较暴力的做超参优化,我们可以把数据预处理也当做超参,搭建端到端的 pipline,然后使用 hyperopt 来做自动选择。
anti-overfitting(-to-dev) with autoML
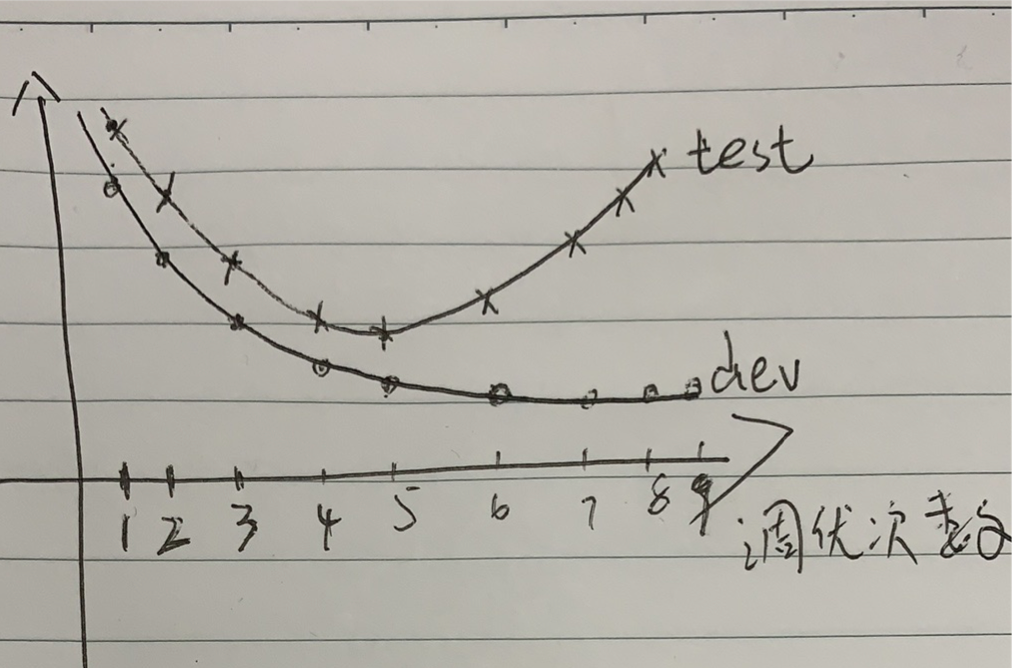
大部分 automl 是根据 dev 集上的效果做方案选择,那就会出现 overfitting-to-dev 的问题。
overfitting-to-dev
借鉴经典的 bias variance trade-off 图,我们可以得到如下的 dev 和 test 集 overfitting 图。随着调优次数的增加,dev 集上的(最优)效果是单调变好的,但次数超过一个阈值后 test 集上的效果就出现 overfitting 了。
anti-overfitting(-to-dev)
- 滑窗自学习 bagging: 使用滑窗自学习得到多组 dev 效果,取平均值对模型方案做排序,最后选用 Top 1(或 Top k bagging) 方案。
- 漏斗模式: 使用第一组 dev 选择 Top N 方案,然后固定这 Top N 方案做一次自学习 (dev2),根据 dev2 的效果重排模型方案,最后选用 Top 1 (Top k bagging) 方案。
上述两种方案在流程上有些区别,但本质上都是在降低模型选择中的 variance。
我个人更倾向于方案 2,使用漏斗模式,在 dev 上表现较差的方案(bias 高),应该是没有出现 overfitting-to-dev 的,而且大概率也不会是最终需要的模型(bias 低 & variance 低)。